LC 187. 重复的DNA序列
题目描述
这是 LeetCode 上的 187. 重复的DNA序列 ,难度为 中等。
所有 DNA 都由一系列缩写为 'A','C','G' 和 'T' 的核苷酸组成,例如:"ACGAATTCCG"。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来找出所有目标子串,目标子串的长度为 $10$,且在 DNA 字符串 s 中出现次数超过一次。
示例 1:1
2
3输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT"
输出:["AAAAACCCCC","CCCCCAAAAA"]
示例 2:1
2
3输入:s = "AAAAAAAAAAAAA"
输出:["AAAAAAAAAA"]
提示:
- 0 <= s.length <= $10^5$
s[i]为'A'、'C'、'G'或'T'
滑动窗口 + 哈希表
数据范围只有 $10^5$,一个朴素的想法是:从左到右处理字符串 $s$,使用滑动窗口得到每个以 $s[i]$ 为结尾且长度为 $10$ 的子串,同时使用哈希表记录每个子串的出现次数,如果该子串出现次数超过一次,则加入答案。
为了防止相同的子串被重复添加到答案,而又不使用常数较大的 Set 结构。我们可以规定:当且仅当该子串在之前出现过一次(加上本次,当前出现次数为两次)时,将子串加入答案。
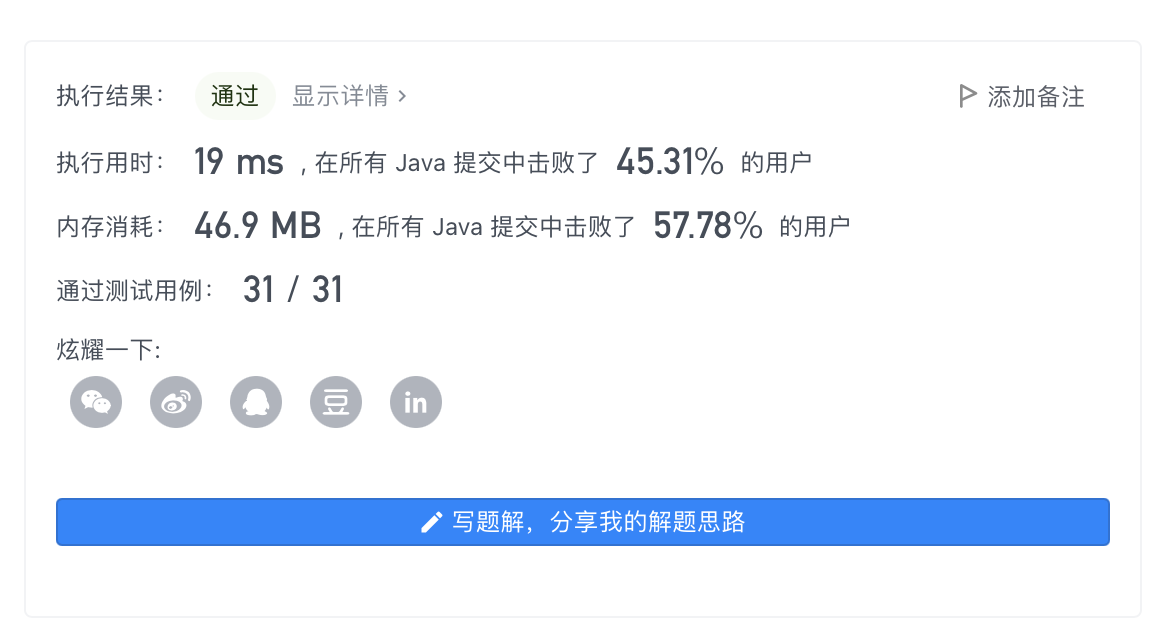
代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14class Solution {
public List<String> findRepeatedDnaSequences(String s) {
List<String> ans = new ArrayList<>();
int n = s.length();
Map<String, Integer> map = new HashMap<>();
for (int i = 0; i + 10 <= n; i++) {
String cur = s.substring(i, i + 10);
int cnt = map.getOrDefault(cur, 0);
if (cnt == 1) ans.add(cur);
map.put(cur, cnt + 1);
}
return ans;
}
}
- 时间复杂度:每次检查以 $s[i]$ 为结尾的子串,需要构造出新的且长度为 $10$ 的字符串。令 $C = 10$,复杂度为 $O(n * C)$
- 空间复杂度:长度固定的子串数量不会超过 $n$ 个。复杂度为 $O(n)$
字符串哈希 + 前缀和
子串长度为 $10$,因此上述解法的计算量为 $10^6$。
若题目给定的子串长度大于 $100$ 时,加上生成子串和哈希表本身常数操作,那么计算量将超过 $10^7$,会 TLE。
因此一个能够做到严格 $O(n)$ 的做法是使用「字符串哈希 + 前缀和」。
具体做法为,我们使用一个与字符串 $s$ 等长的哈希数组 $h[]$,以及次方数组 $p[]$。
由字符串预处理得到这样的哈希数组和次方数组复杂度为 $O(n)$。当我们需要计算子串 $s[i…j]$ 的哈希值,只需要利用前缀和思想 $h[j] - h[i - 1] * p[j - i + 1]$ 即可在 $O(1)$ 时间内得出哈希值(与子串长度无关)。
到这里,还有一个小小的细节需要注意:如果我们期望做到严格 $O(n)$,进行计数的「哈希表」就不能是以 String 作为 key,只能使用 Integer(也就是 hash 结果本身)作为 key。因为 Java 中的 String 的 hashCode 实现是会对字符串进行遍历的,这样哈希计数过程仍与长度有关,而 Integer 的 hashCode 就是该值本身,这是与长度无关的。
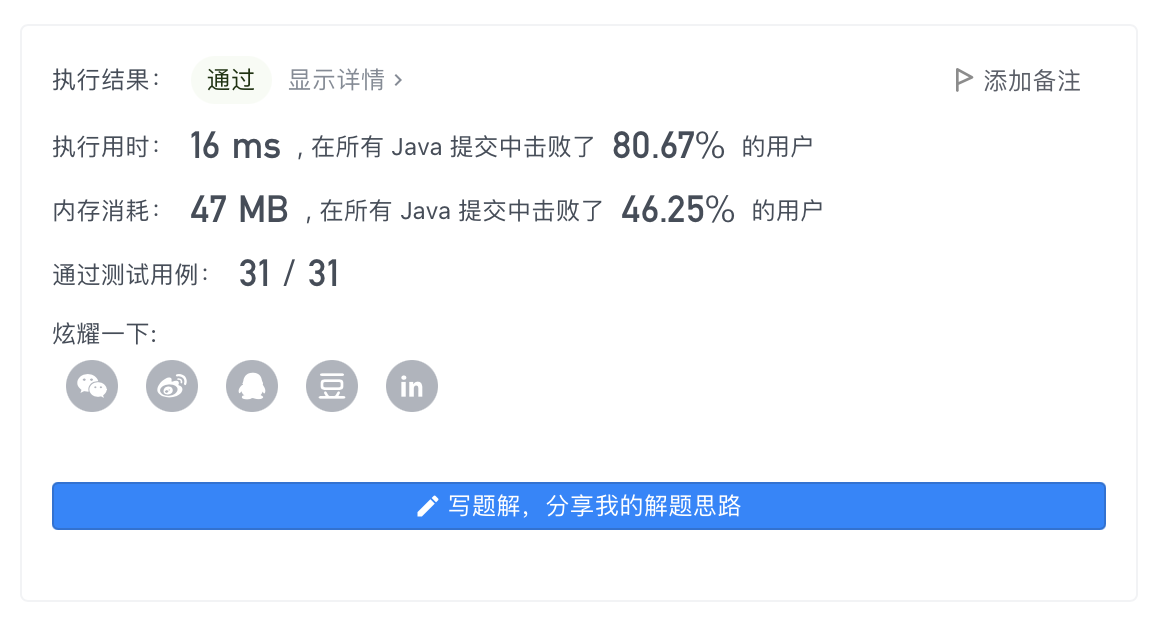
代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
int N = (int)1e5+10, P = 131313;
int[] h = new int[N], p = new int[N];
public List<String> findRepeatedDnaSequences(String s) {
int n = s.length();
List<String> ans = new ArrayList<>();
p[0] = 1;
for (int i = 1; i <= n; i++) {
h[i] = h[i - 1] * P + s.charAt(i - 1);
p[i] = p[i - 1] * P;
}
Map<Integer, Integer> map = new HashMap<>();
for (int i = 1; i + 10 - 1 <= n; i++) {
int j = i + 10 - 1;
int hash = h[j] - h[i - 1] * p[j - i + 1];
int cnt = map.getOrDefault(hash, 0);
if (cnt == 1) ans.add(s.substring(i - 1, i + 10 - 1));
map.put(hash, cnt + 1);
}
return ans;
}
}
- 时间复杂度:$O(n)$
- 空间复杂度:$O(n)$
我猜你问
- 字符串哈希的「构造 $p$ 数组」和「计算哈希」的过程,不会溢出吗?
会溢出,溢出就会变为负数,当且仅当两个哈希值溢出程度与 Integer.MAX_VALUE 呈不同的倍数关系时,会产生错误结果(哈希冲突),此时考虑修改 $P$ 或者采用表示范围更大的 long 来代替 int。
- $P = 131313$ 这个数字是怎么来的?
WA 出来的,刚开始使用的 $P = 131$,被卡在了 $30/31$ 个样例。
字符串哈希本身存在哈希冲突的可能,一般会在尝试 $131$ 之后尝试使用 $13131$,然后再尝试使用比 $13131$ 更大的质数。

最后
这是我们「刷穿 LeetCode」系列文章的第 No.187 篇,系列开始于 2021/01/01,截止于起始日 LeetCode 上共有 1916 道题目,部分是有锁题,我们将先把所有不带锁的题目刷完。
在这个系列文章里面,除了讲解解题思路以外,还会尽可能给出最为简洁的代码。如果涉及通解还会相应的代码模板。
为了方便各位同学能够电脑上进行调试和提交代码,我建立了相关的仓库:https://github.com/SharingSource/LogicStack-LeetCode 。
在仓库地址里,你可以看到系列文章的题解链接、系列文章的相应代码、LeetCode 原题链接和其他优选题解。
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
