LC 430. 扁平化多级双向链表
题目描述
这是 LeetCode 上的 430. 扁平化多级双向链表 ,难度为 中等。
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。
这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
给你位于列表第一级的头节点,请你扁平化列表,使所有结点出现在单级双链表中。
示例 1:1
2
3
4
5输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:
输入的多级列表如下图所示:
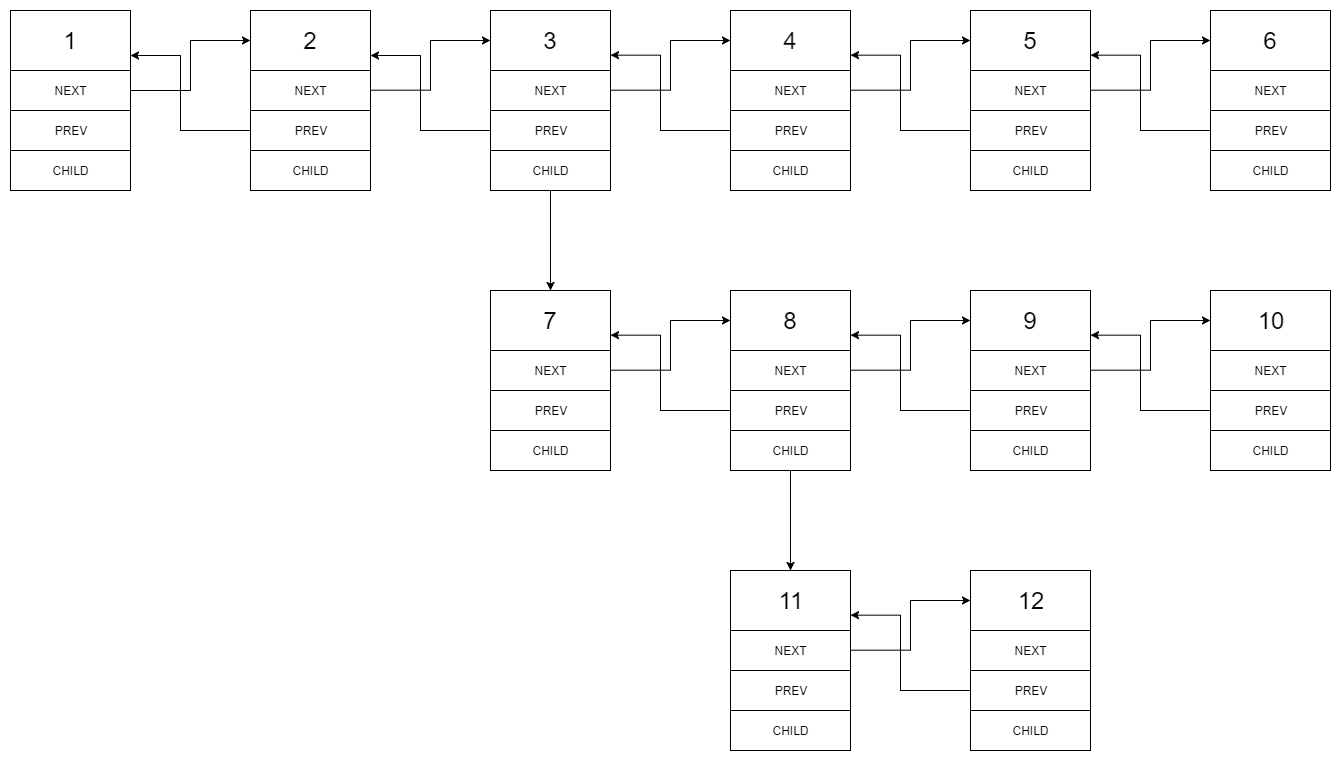
扁平化后的链表如下图:

示例 2:1
2
3
4
5
6
7
8
9
10输入:head = [1,2,null,3]
输出:[1,3,2]
解释:
输入的多级列表如下图所示:
1---2---NULL
|
3---NULL
示例 3:1
2
3输入:head = []
输出:[]
提示:
- 节点数目不超过 $1000$
- $1 <= Node.val <= 10^5$
递归
一道常规链表模拟题。
利用 flatten 函数本身的含义(将链表头为 $head$ 的链表进行扁平化,并将扁平化后的头结点进行返回),我们可以很容易写出递归版本。
为防止空节点等边界问题,起始时建立一个哨兵节点 $dummy$ 指向 $head$,然后利用 $head$ 指针从前往后处理链表:
- 当前节点 $head$ 没有 $child$ 节点:直接让指针后即可,即 $head = head.next$;
- 当前节点 $head$ 有 $child$ 节点:将 $head.child$ 传入
flatten函数递归处理,拿到普遍化后的头结点 $chead$,然后将 $head$ 和 $chead$ 建立“相邻”关系(注意要先存起来原本的 $tmp = head.next$ 以及将 $head.child$ 置空),然后继续往后处理,直到扁平化的 $chead$ 链表的尾部,将其与 $tmp$ 建立“相邻”关系。
重复上述过程,直到整条链表被处理完。
Java 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution {
public Node flatten(Node head) {
Node dummy = new Node(0);
dummy.next = head;
while (head != null) {
if (head.child == null) {
head = head.next;
} else {
Node tmp = head.next;
Node chead = flatten(head.child);
head.next = chead;
chead.prev = head;
head.child = null;
while (head.next != null) head = head.next;
head.next = tmp;
if (tmp != null) tmp.prev = head;
head = tmp;
}
}
return dummy.next;
}
}
C++ 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public:
Node* flatten(Node* head) {
Node* dummy = new Node(0);
dummy->next = head;
while (head != nullptr) {
if (head->child == nullptr) {
head = head->next;
} else {
Node* tmp = head->next;
Node* chead = flatten(head->child);
head->next = chead;
chead->prev = head;
head->child = nullptr;
while (head->next != nullptr) head = head->next;
head->next = tmp;
if (tmp != nullptr) tmp->prev = head;
head = tmp;
}
}
return dummy->next;;
}
};
Python 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution:
def flatten(self, head: 'Optional[Node]') -> 'Optional[Node]':
dummy = Node(0)
dummy.next = head
while head:
if not head.child:
head = head.next
else:
tmp = head.next
chead = self.flatten(head.child)
head.next = chead
chead.prev = head
head.child = None
while head.next:
head = head.next
head.next = tmp
if tmp:
tmp.prev = head
head = tmp
return dummy.next
- 时间复杂度:最坏情况下,每个节点会被访问 $h$ 次($h$ 为递归深度,最坏情况下 $h = n$)。整体复杂度为 $O(n^2)$
- 空间复杂度:最坏情况下所有节点都分布在
child中,此时递归深度为 $n$。复杂度为 $O(n)$
递归(优化)
在上述解法中,由于我们直接使用 flatten 作为递归函数,导致递归处理 $head.child$ 后不得不再进行遍历来找当前层的“尾结点”,这导致算法复杂度为 $O(n^2)$。
一个可行的优化是,额外设计一个递归函数 dfs 用于返回扁平化后的链表“尾结点”,从而确保我们找尾结点的动作不会在每层发生。
Java 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class Solution {
public Node flatten(Node head) {
dfs(head);
return head;
}
Node dfs(Node head) {
Node last = head;
while (head != null) {
if (head.child == null) {
last = head;
head = head.next;
} else {
Node tmp = head.next;
Node childLast = dfs(head.child);
head.next = head.child;
head.child.prev = head;
head.child = null;
if (childLast != null) childLast.next = tmp;
if (tmp != null) tmp.prev = childLast;
last = head;
head = childLast;
}
}
return last;
}
}
C++ 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Solution {
public:
Node* flatten(Node* head) {
dfs(head);
return head;
}
Node* dfs(Node* head) {
Node* last = head;
while (head) {
if (!head->child) {
last = head;
head = head->next;
} else {
Node* tmp = head->next;
Node* childLast = dfs(head->child);
head->next = head->child;
head->child->prev = head;
head->child = nullptr;
if (childLast) childLast->next = tmp;
if (tmp) tmp->prev = childLast;
last = head;
head = childLast;
}
}
return last;
}
};
Python 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution:
def flatten(self, head: 'Optional[Node]') -> 'Optional[Node]':
def dfs(node: 'Node') -> 'Node':
last = node
while node:
if not node.child:
last = node
node = node.next
else:
tmp = node.next
child_last = dfs(node.child)
node.next = node.child
node.child.prev = node
node.child = None
if child_last:
child_last.next = tmp
if tmp:
tmp.prev = child_last
last = node
node = child_last
return last
dfs(head)
return head
- 时间复杂度:$O(n)$
- 空间复杂度:最坏情况下所有节点都分布在
child中,此时递归深度为 $n$。复杂度为 $O(n)$
迭代
自然也能够使用迭代进行求解。
与「递归」不同的是,「迭代」是以“段”为单位进行扁平化,而「递归」是以深度(方向)进行扁平化,这就导致了两种方式对每个扁平节点的处理顺序不同。
已样例 $1$ 为 🌰。
递归的处理节点(新的 $next$ 指针的构建)顺序为:
迭代的处理节点(新的 $next$ 指针的构建)顺序为:
但由于链表本身不存在环,「迭代」的构建顺序发生调整,仍然可以确保每个节点被访问的次数为常数次。
Java 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public Node flatten(Node head) {
Node dummy = new Node(0);
dummy.next = head;
for (; head != null; ) {
if (head.child == null) {
head = head.next;
} else {
Node tmp = head.next;
Node child = head.child;
head.next = child;
child.prev = head;
head.child = null;
Node last = head;
while (last.next != null) last = last.next;
last.next = tmp;
if (tmp != null) tmp.prev = last;
head = head.next;
}
}
return dummy.next;
}
}
C++ 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Solution {
public:
Node* flatten(Node* head) {
Node dummy(0);
dummy.next = head;
for (; head != nullptr; ) {
if (!head->child) {
head = head->next;
} else {
Node* tmp = head->next;
Node* child = head->child;
head->next = child;
child->prev = head;
head->child = nullptr;
Node* last = head;
while (last->next) last = last->next;
last->next = tmp;
if (tmp) tmp->prev = last;
head = head->next;
}
}
return dummy.next;
}
};
Python 代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution:
def flatten(self, head: 'Optional[Node]') -> 'Optional[Node]':
dummy = Node(0)
dummy.next = head
while head:
if not head.child:
head = head.next
else:
tmp = head.next
child = head.child
head.next = child
child.prev = head
head.child = None
last = head
while last.next:
last = last.next
last.next = tmp
if tmp:
tmp.prev = last
head = head.next
return dummy.next
- 时间复杂度:可以发现,迭代写法的扁平化过程并不与遍历方向保持一致(以段为单位进行扁平化,而非像递归那样总是往遍历方向进行扁平化),但每个节点被访问的次数仍为常数次。复杂度为 $O(n)$
- 空间复杂度:$O(1)$
最后
这是我们「刷穿 LeetCode」系列文章的第 No.430 篇,系列开始于 2021/01/01,截止于起始日 LeetCode 上共有 1916 道题目,部分是有锁题,我们将先把所有不带锁的题目刷完。
在这个系列文章里面,除了讲解解题思路以外,还会尽可能给出最为简洁的代码。如果涉及通解还会相应的代码模板。
为了方便各位同学能够电脑上进行调试和提交代码,我建立了相关的仓库:https://github.com/SharingSource/LogicStack-LeetCode 。
在仓库地址里,你可以看到系列文章的题解链接、系列文章的相应代码、LeetCode 原题链接和其他优选题解。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
